从零开始搭建K8s集群,一般网上的教程都会让大家提前准备三台机器,分别进行环境的安装。其实我们可以通过VMware虚拟机的克隆机制 直接复制得到虚拟机。这样就只需要处理一台的环境即可。
k8s环境安装并配置 VMware 安装centos7之后, 用这台虚拟机用作master,安装并配置环境之后,再直接克隆出两个node即可
角色
IP
备注
k8smaster
192.168.31.190
安装环境只做一次即可
k8snode1
192.168.31.191
克隆虚拟机,并改MAC地址、改hostname
k8snode2
192.168.31.192
克隆虚拟机,并改MAC地址、改hostname
环境配置 防火墙、selinux、swap 部署k8s,需要关闭防火墙、禁用selinux、swap
关闭防火墙的原因(nftables后端兼容性问题,产生重复的防火墙规则)
禁用selinux的原因(关闭selinux以允许容器访问宿主机的文件系统)
禁用swap的原因(swap将部分内存数据存放到磁盘中,这样会使性能下降)
依次执行下列命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 systemctl stop firewalld systemctl disable firewalld sed -i 's/enforcing/disabled/' /etc/selinux/config sed -ri 's/.*swap.*/#&/' /etc/fstab hostnamectl set-hostname k8smaster cat >> /etc/hosts << EOF 192.168.31.190 k8smaster 192.168.31.191 k8snode1 192.168.31.192 k8snode2 EOF cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sysctl --system yum install ntpdate -y ntpdate time.windows.com reboot
安装Docker 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo yum list docker-ce --showduplicates|grep "^doc" |sort -r yum -y install docker-ce-19.03.15-3.el7 docker-ce-cli-19.03.15-3.el7 containerd.io cat >> /etc/docker/daemon.json << EOF { "registry-mirrors": ["https://xxxx.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"] } EOF systemctl enable docker systemctl start docker docker version
显示如下输出,docker安装就完成了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 Client: Docker Engine - Community Version: 24.0.2 API version: 1.40 (downgraded from 1.43) Go version: go1.20.4 Git commit: cb74dfc Built: Thu May 25 21:55:21 2023 OS/Arch: linux/amd64 Context: default Server: Docker Engine - Community Engine: Version: 19.03.15 API version: 1.40 (minimum version 1.12) Go version: go1.13.15 Git commit: 99e3ed8919 Built: Sat Jan 30 03:16:33 2021 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.6.21 GitCommit: 3dce8eb055cbb6872793272b4f20ed16117344f8 runc: Version: 1.1.7 GitCommit: v1.1.7-0-g860f061 docker-init: Version: 0.18.0 GitCommit: fec3683
配置K8s环境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 cat > /etc/yum.repos.d/kubernetes.repo << EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF yum -y install kubelet-1.22.0 kubeadm-1.22.0 kubectl-1.22.0 vim /etc/sysconfig/kubelet KUBELET_EXTRA_ARGS="--cgroup-driver=systemd" systemctl daemon-reload systemctl enable kubelet
可能会出现的问题
kubeadm init执行的时候出现:unexpected kernel config: CONFIG_CGROUP_PIDS。这个问题需要升级Linux内核
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 grub2-editenv list rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm yum --disablerepo="*" --enablerepo="elrepo-kernel" list available yum --enablerepo=elrepo-kernel install kernel-ml cp /etc/default/grub /etc/default/grub_bakgrub2-mkconfig -o /boot/grub2/grub.cfg systemctl enable docker.service reboot cat /boot/grub2/grub.cfg | grep -v rescue | grep ^menuentrygrub2-set-default 'CentOS Linux (6.3.5-1.el7.elrepo.x86_64) 7 (Core)' reboot
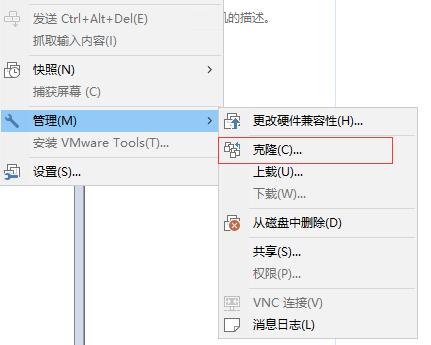
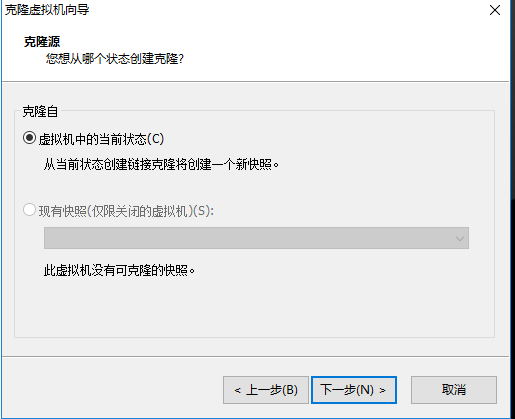
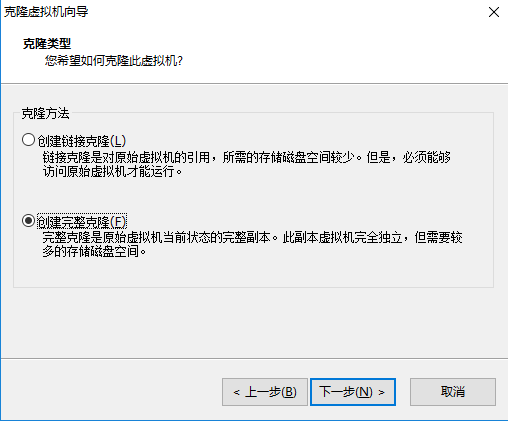
克隆虚拟机机 首先关闭虚拟机 - 设置 - 克隆(克隆之后需要修改两处:1.MAC地址 2.HostName)
然后记得 在虚拟机的 网络适配器高级设置 中修改MAC地址
1 2 3 4 hostnamectl set-hostname k8snode1 reboot
第三台也是一样的操作。
master安装k8s 用kubeadm init命令来安装,kubeadm的版本和kubernetes-version需要一致,如下都为1.22。
1 kubeadm init --apiserver-advertise-address=192.168.31.190 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.22.10 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
出现下面的日志就安装成功了
1 2 3 4 5 6 7 8 9 10 11 Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster . Run "kubectl apply -f [podnetwork] .yamLu with one of the options listed at: https: / /kube rnetes. io/docs /concepts/cluster- administration/ addons I Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.31.190:6443 --token 2luxh6.uhhj74j5oj6xfdtv \ --discovery-token-ca-cert-hash sha256:4f558182265bee13182b2480ba7180a867a5f3b93ab18c82c4a0d542a4c2poi1
配置kubectl工具 1 2 3 mkdir -p $HOME /.kubesudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/configsudo chown $(id -u):$(id -g) $HOME /.kube/config
查看节点状态
能够看到,目前有一个master节点已经运行了,但是还处于未准备状态
node1加入集群 复制 上面 master安装成功之后的输出的kubeadm join命令,默认的token有效期为24小时,当过期之后,该token就不能用了,这时可以使用如下的命令创建token
1 2 kubeadm token create --ttl 0
将该token替换上面的join命令中的token
1 2 kubeadm join 192.168.31.190:6443 --token 7auxee.exh5uov0uorusyl \ --discovery-token-ca-cert-hash sha256:4f558182265bee13182b2480ba7180a867a5f3b93ab18c82c4a0d542a4c2poi1
Master部署CNI网络插件 1 kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
如果网络访问不了,也可以先在自己电脑上下载完成之后,再传输到虚拟机上,执行kubectl apply -f kube-flannel.yml
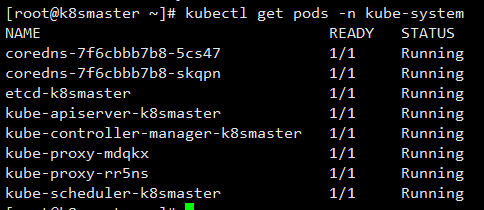
然后等待pod全部安装,进入running状态
1 kubectl get pods -n kube-system
这个时候,我们再次查看节点状态就都是Ready状态了
如果node节点还不是Ready状态 需要先删除节点,再重置
1 kubectl delete node k8snode1
然后在node1机器上执行重置
再次join
1 2 kubeadm join 192.168.31.190:6443 --token 7auxee.exh5uov0uorusyl \ --discovery-token-ca-cert-hash sha256:4f558182265bee13182b2480ba7180a867a5f3b93ab18c82c4a0d542a4c2poi1
回到master机器上,再次查看node状态
集群健康检查 在master机器上执行健康检查状态
输出如下
1 2 3 4 NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true","reason":""}
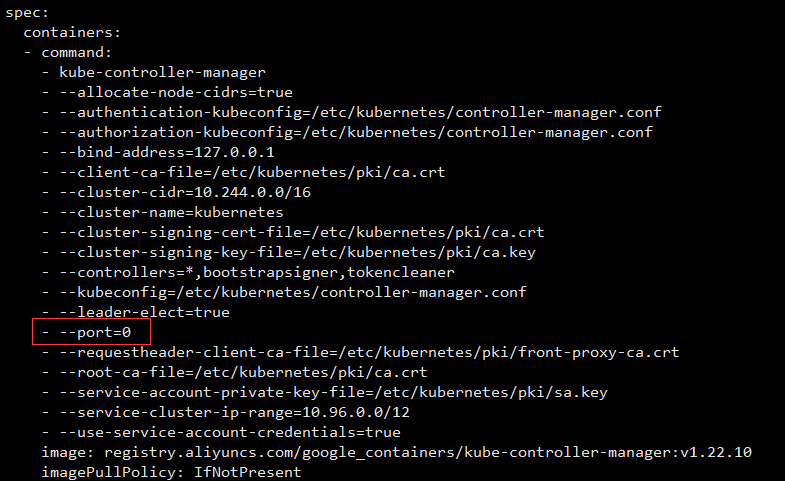
如果出现状态出现 Unhealthy,就需要删掉配置中- --port=0 这一行
1 2 systemctl restart kubelet
至此,整个搭建过程就完成了。
参考来源: